


















Zde se dozvíte základní informace o hyperkonvergované infrastruktuře Nutanix - moderním a optimálním řešení pro datová centra. Pro rychlou orientaci použijte tyto odkazy:
-
Obecný úvod o hyperkonvergované infrastruktuře
-
Video - detailnější vysvětlení technologie Nutanix
-
Výhody hyperkonvergované infrastruktury
-
Referenční case study a video se zákazníkem
-
Možnost vyzkoušení - Proof of Concept
-
Technické detaily
______________________________________________________________________________
Obecný úvod o hyperkonvergované infrastruktuře
Tradiční třívrstvá infrastruktura byla v průběhu let dopilována k dokonalosti, jenže omezení daná jejími principy již nelze obejít ani těmi nejrychlejšími NVMe disky nebo SAN. V minulosti jsme odtrhli data od procesorů a komplikovaně řešíme vzniklé úzké hrdlo. Co když data zase vrátíme hezky do serverů a obejdeme tak nutnost použití SAN? Skoro kacířská myšlenka, když jsme ji tolik let vyvíjeli. Zásadní překážka pro nasazení hyperkonvergované infrastruktury (HCI) je právě tato naprosto přirozená rezistence ke změně. Pokud se přes ni ale přeneseme, otevřou se nám výhody HCI v celé své kráse.
Jednoduché, efektivní a flexibilní řešení
Hyperkonvergovaná infrastruktura je v principu a z pohledu architektury až geniálně jednoduchá. Představte si ji jako skupinu serverů zapojených do LAN. Skupina znamená cokoliv mezi třemi a tolika, kolik unese podlaha vašeho sálu. Na rozdíl od klasické třívrstvé architektury mají tyto servery v sobě i disky, tedy úložiště dat. Hardware je tedy triviálně komoditní a z toho plynou dvě zásadní výhody – nízká cena a snadná dostupnost. To, co dělá z těchto obyčejných serverů vysoce dostupné, odolné, neomezeně škálovatelné, univerzální a efektivní řešení, je softwarová vrstva Nutanix. Díky ní získáte zcela plnohodnotné enterprise řešení se vším, na co jste zvyklí z moderního datacentra. Tedy skoro se vším! Budete muset oželet výpadky při aktualizacích nebo horké chvilky při rozšiřování kapacit.
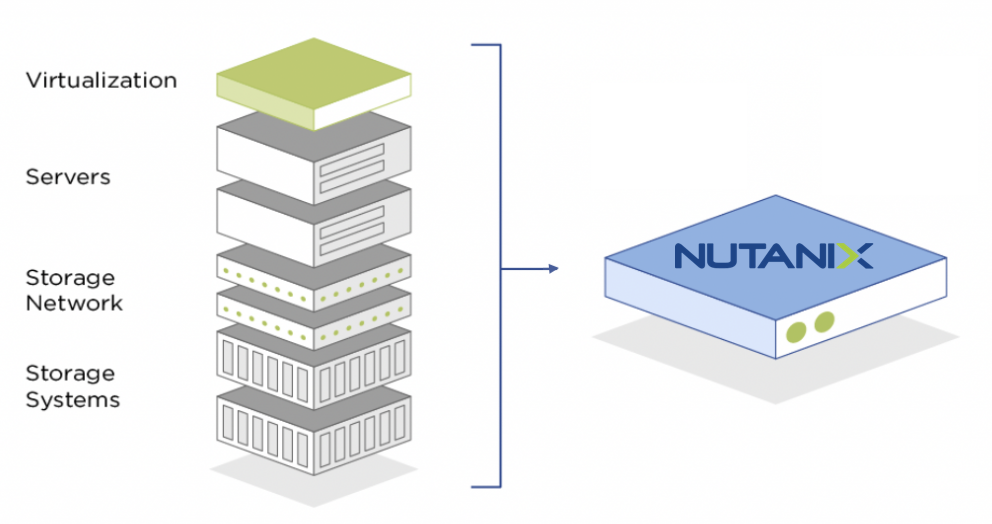
Univerzálnost hyperkonvergované infrastruktury plyne z naprosté flexibility, s jakou lze cluster budovat a rozšiřovat. Může to být minicluster o 3 serverech s celkem třemi procesory, opačný extrém je pak monstrum splňující certifikaci pro provoz SAP HANA. Nebo infrastruktura pro VDI, databázový server, PACS či cokoliv jiného… ostatně i giganti jako je Google či Facebook využívají hyperkonvergovaná řešení.
Nutanix jako lídr
Softwarová vrstva Nutanix nabízí mimo jiné největší svobodu ohledně volby HW platformy nebo provozovaného hypervizoru. Když se rozhodnete pro integrovaný nativní hypervizor Nutanix, ušetříte za licence VMware nebo Hyper-V. Pokud ale chcete používat jiný hypervizor, nic tomu nebrání. Ať chceme nebo ne, hyperkonvergovaná infrastruktura je budoucnost datových center. A proč vlastně nechtít?
______________________________________________________________________________
______________________________________________________________________________
Výhody hyperkonvergované infrastruktury
• nízké TCO v porovnání s tradiční infrastrukturou
• vysoká míra automatizace a nízké nároky na správu a lidské zdroje
• zásadní úspora místa v serverovně, nákladů na chlazení i spotřeby elektřiny
• neomezená škálovatelnost, flexibilita a postupný růst řešení
• komfort a rychlost cloudových služeb pro on-premise nasazení
• robustní řešení s nativní podporou DR scénářů a replikací
• univerzální řešení jak z pohledu velikosti, tak provozované zátěže
• stovky VDI nebo téměř milion IOPS ve 2U appliance
• svoboda volby hardwarové platformy i hypervizoru
______________________________________________________________________________
Referenční case study a video se zákazníkem
Jednou z našich referenčních instalací je i infrastruktura pro zajištění provozu PACS systémů ve Fakultní nemocnici v Motole. Jedná se o zásadní a kriticky důležitou aplikaci na straně zákazníka, na které doslova závisí lidské životy. Řešení postavené na platformě Nutanix splnilo náročné technické a výkonnostní požadavky při zachování nízkých nákladů za pořízení i provoz. Z technického pohledu jde o dva oddělené clustery s vysokou diskovou kapacitou ve dvou lokalitách zajišťující vysokou dostupnost. Kromě spolehlivosti zákazník velmi ocenil i nízké nároky na správu řešení, kvality použitého hypervisoru Nutanix Acropolis, bezproblémovou rozšiřitelnost a také univerzálnost použití i pro jiné systémy než právě PACS. Jak hodnotí naši implementaci Vedoucí odboru IS ve FN Motol pan Ing. Martin Voříšek můžete vidět na následujícím videu:
______________________________________________________________________________

Samozřejmostí pro naše zákazníky je možnost vyzkoušet si nabízené řešení přímo ve svém prostředí a případně i na svých datech. Pokud vás Nutanix zaujal a zvažujete pořízení hyperkonvergované infrastruktury, pak má realizace proof of concept (POC) několik zásadních výhod. Kromě demonstrace faktu, že Nutanix opravdu funguje tak, jak slibuje, lze pomocí POC upřesnit sizing a jasně potvrdit optimalizace a úspory plynoucí z využití hyperkonvergované infrastruktury.
Vlastní POC probíhá typicky zapůjčením 2U appliance se čtyřmi nody, tvořící cluster. Na tento cluster vám pomůžeme nasadit vaše aplikace, otestovat požadované scénáře, změřit výkonnost a následně po několika týdnech provozu vyhodnotit získaná data. Testovací konfiguraci i průběh POC vždy maximálně přizpůsobujeme požadavkům zákazníka, takže POC probíhá přesně podle vašeho scénáře. Potřebujete rozšířit kapacitu datacentra, blíží se vaše servery a diskové pole konci životnosti nebo se potýkáte s výpadky či výkonnostními problémy? Neváhejte nás kontaktovat a ukážeme vám, že to jde i jednoduše a lépe.
______________________________________________________________________________
Technické detaily
Základní technické principy hyperkonvergovaného řešení Nutanix
Každé produkční prostředí datového centra musí pro svůj provoz obsahovat dva klíčové elementy - samotné funkce infrastruktury a funkce managementu a řízení. Zatímco požadavky na provozní část jsou většinou jasně definované, prostředí pro správu a řízení se často potýká s nejasnými požadavky, a navíc je zásadně postiženo fragmentací a roztříštěností. Jednak tím, jak se jednotlivé funkce dynamicky vyvíjejí, a také tím, že je nutné integrovat technologie a postupy různých výrobců a pracovat s jejich často různou filozofií a přístupem k jednotlivým funkcionalitám.
Implementace hyperkonvergovaného řešení Nutanix podobně jako třívrstvá architektura také obsahuje provozní vrstvu - AOS a funkci správy a řízení prostředí Nutanix Prism. Vzhledem k tomu, že vývoj a design obou vrstev postupuje koordinovaně, je každá funkcionalita řešena tak, aby byla dobře řiditelná a zároveň dávala smysl v existujících postupech a workflow. Díky tomu je možné obě vrstvy nejen efektivně využít, ale je možné mnoho složitých postupů a funkcí zcela automatizovat.
Ze zkušeností při provozu datových center vidíme zajímavý rozpor, kdy je při provozu a rozšiřování tradičních infrastruktur zcela logické, že výpočetní zdroje automaticky rostou tak, jak roste fyzický počet a velikost výpočetních prostředků, přičemž u vrstvy správy a managementu ale k automatickému rozšíření většinou nedochází. Instalace nového zařízení s novými vlastnostmi často znamená změnu workflow a rekonfiguraci existujícího prostředí pro správu a dohled. V prostředí Nutanix Prism je však vrstva managementu a řízení plně distribuovaná a automaticky roste stejně tak, jak roste infrastruktura. Nedochází tedy k přetěžování jednotlivých prvků managementu, a navíc při rozšíření funkcionality dojde automaticky k rozšíření možností v jiných částech managementu. Například automatické rozšíření možností virtuální sítě při implementaci SW nebo HW firewallu, nebo automatické rozšíření možnosti správy virtuálních strojů v případě nasazení prostředí H/A. Další příjemný důsledek této filozofie je, že se prostředí Nutanix spravuje stejně hladce bez ohledu na velikost infrastruktury.
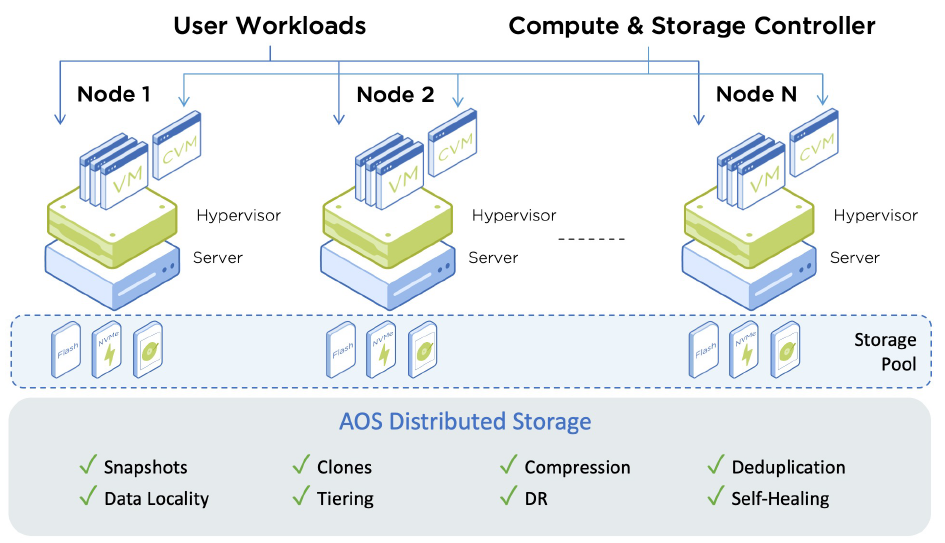
Pro základní pochopení, jak to celé vlastně funguje, je třeba popsat fundamentální prvek hyperkonvergovaného řešení Nutanix – CVM neboli Control Virtual Machine. Jde o speciální virtuální stroj, který má na starosti všechny funkcionality Nutanixu, jako jsou například řízení a provoz distribuovaného datového úložiště, distribuovaná síť, správa a management. CVM vlastně obsahuje kompletní logiku, funkce a řízení, kromě vrstvy hypervizoru. Toto architektonické rozhodnutí je klíčem k tomu, proč je možné provozovat Nutanix i pod jinými hypervizory jako VMware, HyperV, Xen a vlastním AHV hypervizorem. Ze stejného důvodu není Nutanix omezen jen na procesory x86_64, ale je ho možné provozovat i na procesorech IBM Power. Další výhodou řešení pomocí CVM je to, že tento virtuální stroj má k dispozici vše, co potřebuje pro svůj běh, včetně nástrojů pro řízení a dohled. Díky tomu je infrastruktura schopna absorbovat velmi drastické hardwarové výpadky, přičemž má zároveň možnost efektivně využít zbylé prostředky. Často se stává, že neselže celý HW blok (server), ale třeba jen část paměti, část disků, řadič apod. Pokud například selže řadič disků, Nutanix je schopen tento HW využít alespoň jako výpočetní zdroj, přičemž data poskytují ostatní části infrastruktury. Důležité je, že k těmto rekonfiguracím dochází automaticky bez nutnosti zásahu obsluhy. Tento krátký úvod do funkcionalit CVM je důležitý proto, aby byla jasnější celková filozofie prostředí Nutanix.
Funkce pro provoz moderních datových center
Provoz tradičních infrastruktur (třívrstvá, monolitická apod.) po dobu své existence ukázal nutnost a užitečnost pokročilých funkcí datových center a hyperkonvergovaná infrastruktura může tyto principy využít a dále rozvinout. Jedná se především o funkce datových úložišť, snapshoty, synchronní a asynchronní repliky, klonování dat, síťové bezpečnostní funkce, segmentace, funkce ochrany proti výpadku, datové redundance, RAID, Storage Tiering apod. Díky tomu, že prostředí Nutanix obsahuje všechny vrstvy infrastruktury a zároveň má dostatek informací o provozu, je možné dynamicky měnit nastavení jednotlivých parametrů a automaticky generovat složité řetězce událostí. Dobrý příklad je situace, kdy jeden virtuální stroj negativně ovlivňuje celou infrastrukturu, tudíž je výhodné ho realokovat. V tradiční infrastruktuře je třeba řešit repliky, replikační páry, datovou koherenci a konzistenci dat, skript pro převod replikačních párů apod. V prostředí Nutanix a nastavené replikace pouze zvolíme, kam chceme migrovat. Systém automaticky spustí kaskádu procesů jak na úrovni storage, sítí, tak i virtuálního stroje, na jejichž konci je doplnění snapshotu k poslední replice a start VM v jiné lokalitě, takže i v případě asynchronní replikace je v momentě plánovaného přechodu nulová ztráta dat. Navíc se všechny aktivity generují a řetězí automaticky. Další zajímavý scénář je například neočekávaná změna charakteru zátěže celých skupin virtuálních strojů, např. VDI, kdy jednotlivé skupiny strojů chaoticky zatěžují datové úložiště. Z pohledu diskového subsystému se jedná o náhodné čtení, kde není co optimalizovat. Nutanix je však schopen rozpoznat, že se jedná o skupinu VM s podobnou zátěží, a jedna čtecí operace může obsloužit celou skupinu virtuálních strojů. Celou situaci výrazně ulehčuje schopnost Nutanixu řetězit dlouhé řady klonů a snapshotů bez penalizace výkonnosti, což efektivně snižuje nároky na diskovou kapacitu, a tak výrazně urychluje čtecí operace pro skupiny podobných virtuálních strojů.
Základní prvky hyperkonvergované infrastruktury Nutanix
- AOS Distributed Storage - Distribuované datové úložiště
- AHV virtualizace - Nutanix hypervizor (ev. hypervizory třetích stran)
- Scale Out Storage services - Distribuované datové nebo objektové služby.
- Advanced Virtual Networking - Nutanix Flow - Virtuální distribuované síťové služby.
- Další zajímavé funkce
AOS Distributed Storage
Zcela základním a nezbytným prvkem pro provoz hyperkonvergované infrastruktury je distribuované datové úložiště, které umožňuje spojit dostupnou diskovou kapacitu do jednoho softwarově definovaného úložiště, poskytujícího prostor pro jednotlivé virtuální stroje, aplikace a hypervizor. Diskové úložiště musí podporovat všechny výše zmíněné pokročilé funkce a zároveň musí plně podporovat hypervizory VMware® vSphere, Microsoft® Hyper-V, Citrix®. Pojďme si popsat zásadní technologie, které umožňují provoz distribuovaného datového úložiště v enterprise prostředí.
Podpora různých hypervizorů a transportních protokolů
Jednotlivé hypervizory používají pro svůj provoz různé transportní protokoly jako iSCSI, NFS a SMB. Nutanix umí obsloužit všechny z nich, a to nejen pro samotný provoz virtualizace, ale je schopen poskytovat datové služby i pro ostatní systémy, takže je možné použít Nutanix jako distribuované diskové pole.
Flexibilní redundance
Nutanix umožňuje zvolit míru redundance jak pro celkový Nutanix Cluster, tak pro jednotlivé VM. Míra redundance je definovaná faktorem replikace. Standardně postačuje faktor 2, což znamená, že se všechna data ukládají ve dvou kopiích. Pro obzvlášť kritické systémy je vhodné zvolit faktor replikace 3. Sytém je tak schopen absorbovat 2 současné HW výpadky. Vzhledem k tomu, že jsou data uložena minimálně ve dvou kopiích, je možné definovat ke každému datovému objektu redundantní cestu. Díky tomu je možné přistoupit k datům i v případě částečné nebo naprosté nedostupnosti nebo výpadku výpočetního nodu (serveru). Tato funkcionalita je klíčová pro dva typy událostí:
- Plánované updaty nebo plánované výpadky. V tomto případě převezme bez výpadku provoz zbývající část výpočetního clusteru.
- Neplánované výpadky a poruchy. I v tomto případě převezme provoz zbytek infrastruktury, nicméně Nutanix začne přepočítávat a distribuovat další redundantní data, aby byla splněna podmínka dvou nebo tří redundantních kopií. Vzhledem k tomu, že se na rekonstrukci podílí celý zbytek infrastruktury, dokáže Nutanix absorbovat a opravit takový typ výpadku velmi rychle.
Kontrola integrity dat
Během provozu Nutanix kontroluje, zda nedošlo na HW úrovni k dezintegraci dat. Ne vždy je HW závada diskového subsystému zcela zjevná. Občas se stává, že během provozu dochází během čtecích operací k chybám náhodného přehazování bitů (Bit Rot). Protože Nutanix kontroluje datovou integritu nejen při každém čtení, ale i průběžně, je schopen tyto chyby detekovat, následně je opravit, a zároveň izolovat z provozu vadné datové segmenty. Tato technologie zajišťuje ochranu proti plíživé dezintegraci dat, která je často detekována až v době, kdy už jsou škody neopravitelné a daleko za retencí zálohovacích systémů.
Availability domény
Ve velkých datových centrech může dojít a dochází k výpadku celých bloků HW, například celých racků nebo multiserverových kontejnerů. Důvod nemusí být jen výpadek napájení, ale třeba pouhý výpadek konektivity a podobně. Extrémní zvyšování počtu redundantních kopií by bylo značně neefektivní. Jednoduchá a efektivní obrana proti těmto typům výpadků jsou právě availability domény. Availability domény jsou definice, díky kterým je Nutanix schopen určit, kde se konkrétní datový objekt nachází, takže nepřipustí zápis redundantní kopie do stejné availability domény. Někdy se této funkci říká také Rack/Block awareness. Díky tomu je možné, aby byl Nutanix schopen absorbovat simultánní výpadek celého bloku nebo racku bez ztráty dat výpadku provozu.
Nutanix Distributed Storage fabric obsahuje mnoho funkcí pro optimalizaci výkonu.
Data Locality
Data locality je unikátní funkce, která zcela dramatiky zlepšuje parametry výkonnosti diskového subsystému, a zároveň nepotřebuje žádné speciální hardwarové prostředky. Architektonická úvaha je přitom zcela jednoduchá. Nejrychlejší diskové operace jsou vždy ty lokální, protože s sebou nenesou latenci celé infrastruktury. Nutanix navíc disponuje nejen všemi informacemi o datech, ale i o umístění virtuálního stroje, a je schopen data proaktivně kolokovat tak, aby všechna data byla pro virtuální stroj lokálně dostupná. Tato funkce pracuje automaticky a v případě přesunutí VM na jiný nod / server, Data Locality automaticky přesouvá data na odpovídající výpočetní nod.
Automatický disk tiering
Automatický disk tiering eliminuje nutnost definovat a manuálně řídit využití jednotlivých diskových tierů. Je tedy možné, a dokonce je výhodné kombinovat různé výpočetní nody s různě rychlým nebo velkým diskovým subsystémem či použít hybridní konfigurace jako NVMe a SSD nebo SSD a HDD. NVMe a SSD vrstvu navíc využívá průběžně tak, aby nevznikaly hotspoty (místa s nadměrným opotřebením disku), takže nevzniká nadměrné opotřebení (SSD wearing) disků.
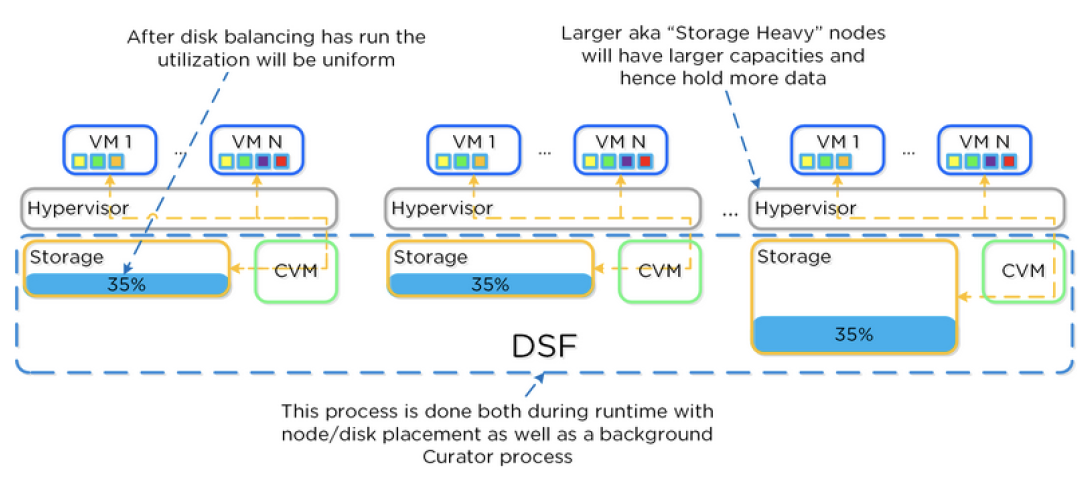
Automatic Disk Balancing
Vzhledem k tomu, že Nutanix umožňuje použití různých kombinací nodů s různou kapacitou a rychlostí, automatický Disk Balancing zajišťuje rovnoměrné rozložení dat i v takto heterogenní konfiguraci bez nutnost manuálního rebalancování.
Shadow Clones
Technologie stínových kopií dramaticky zlepšuje výkonnost u systémů, které jsou definovány jako klon z Master Image, typicky např. u VDI Citrix MCS Master VM nebo VMware View replica disks. V těchto případech je jedna čtecí operace schopna obsloužit rozsáhlé skupiny serverů. Použití shadow klonů zároveň umožňuje prakticky neomezené řetězení klonů bez penalizace výkonu diskového subsystému. Shadow klony také dramaticky zvyšují efektivitu využití diskového subsystému.
Optimalizace diskové kapacity
- Deduplikace
Nutanix nabízí dvě možnosti, jak deduplikovat data a zvýšit rychlost aplikací.
První možností je Inline deduplikace, která zabraňuje vzniku duplicitních dat ve vyrovnávací paměti a SSD vrstvě.
Další možností je globální post proces deduplikace, která omezuje duplicity v kapacitním tieru a tak výrazně zefektivňuje možnost jeho využití.
Pro identifikaci a fingerprinting duplikátů Nutanix využívá hardwarovou funkci SHA-1 Hash, takže dopady na výkon jsou minimální a většinou dochází díky úspoře prostoru ke zrychlení.
- Komprese
Komprese může být podobně jako deduplikace inline nebo post proces se stejnými přínosy. Deduplikaci i kompresi lze vzájemně kombinovat a obě funkcionality jsou navrženy tak, aby deduplikace umožňovala kompresi a komprese umožňovala deduplikaci.
- Erasure Coding EC-X
EC-X algoritmus přináší výraznou úsporu místa. S rostoucím počtem nodů roste možnost ušetřit diskovou kapacitu až do maximální hodnoty 75% dostupné kapacity z hrubé kapacity použitých disků. Primární účel EC-X je eliminovat negativní dopady zdvojování dat pro replikační faktor. EC-X se svými vlastnostmi podobá technice RAID, ale nezpůsobuje zpomalení zápisových operací.
AHV virtualizace
Virtualizace AHV je nativní virtualizační prostředí, které je součástí Nutanix řešení. Lze samozřejmě použít i jiný podporovaný hypervizor, ale AHV je možné v prostředí Nutanix použít bez dalších licenčních požadavků a zároveň nabízí všechny důležité vlastnosti, které jsou pro běh datových center provozovaných i v těch nejpřísnějších režimech zapotřebí.
O možnosti operací s virtuálním strojem není nutné mluvit, nicméně Nutanix umožňuje další zajímavé funkce.
- Image Management - Centrální správa instalačních médii a master image
Nutanix se neomezuje jen na možnost využití vlastních formátů, ale umožňuje i využít externí formáty, např. .raw, .vhd, .vdmk, .vdi a .qcow2. Takto výrazně minimalizuje nutnost manuální konverze již existujících a Master Image a přináší zásadní úsporu času a úsilí při definování více různých verzí Master Image pro různé hypervizory.
- AOS Dynamic Scheduling (ADS)
ADS neustále vyhodnocuje stav a výkonnostní charakteristiky a automaticky vyhodnocuje, kam je nejvýhodnější umístit nové VM nebo instalační médium. ADS umí sledovat i anomální chování virtuálních strojů a pomocí AI proaktivně rebalancovat jejich rozmístění. AOS samozřejmě respektuje nastavení Affinity a AntiAffinity pravidel.
Affinity a AntiAffinity pravidla
Protože Nutanix umožňuje kombinovat různé hardwarové konfigurace výpočetních nodů, může být pro virtuální stroj výhodné preferovat nebo uzamknout jej na konkrétní HW typ nebo přímo konkrétní nody. Důvody mohou být např. licenční, kapacitní (např. konkrétní nody jsou navrženy pro povoz SAP HANA) nebo hardwarové (např. některé nody obsahují GPU, které VM potřebuje pro svůj běh). Affinity pravidla toto uzamknutí dovolují.
AntiAffinity pravidla jsou výhodná v momentě, kdy není žádoucí, aby dva virtuální stroje běžely na stejném výpočetním nodu. Tento důvod může být například buď funkční, kdy se dvě VM negativně ovlivňují, nebo to není architektonicky vhodné z hlediska zvýšení dostupnosti.
- Live Migration
Live Migrace umožňují přesunout VM za běhu na jiný výpočetní node. Tato funkce je důležitá zejména při aktualizacích či údržbě HW, kdy je možné provádět tyto činnosti za běhu bez dopadu na provoz. Live migrace je navíc možná v případě synchronní replikace i na zcela jiný Nutanix cluster. Lze tedy provést DR řízený failover a failback za provozu bez výpadku VM.
- Cross-Hypervisor Migrace
Nutanix DFS umožňuje migrovat mezi ESXi a AHV. Tato vlastnost je zajímavá v případě, že se rozhodnete zachovat např. v primární lokalitě váš stávající hypervizor, zatímco v DR lokalitě může běžet Nutanix AHV.
- Automatické HA
V případě výpadku HW jednoho nodu Nutanix automaticky spustí zasažené VM na jiném nodu. V případě optimální alokace N+1 probíhá vše automaticky, nicméně lze řešit i situace, kdy je Nutanix přealokován, a HW prostředky zbývajících nodů tedy neumožňují spuštění všech VM. Pokud k tomu dojde, je možné definovat kritické systémy a předalokovat prostředky, aby bylo možné zachovat provoz alespoň těchto kritických systémů. Tato vlastnost je výhodná zejména pokud systém provozuje jak kritické systémy, tak zároveň např. testovací a vývojová prostředí, která tak kritická nejsou.
- AHV Turbo
AHV Turbo kombinuje dvě techniky urychlení I/O operací.
Pokud host plně podporuje Vrit-IO PCI, Nutanix umožňuje obejít vrstvu virtualizovaného I/O Stacku. Tato vlastnosti výrazně zkracuje latence I/O operaci.
Druhá vlastnost jsou vícekanálové operace. Pro jednoduchou ilustraci problému předpokládejme, že máme jedno VM, které provozuje databázi a zpracovává malé a náhodné segmenty dat, a zároveň spustíme zálohu, která paralelně zpracovává sice málo, ale velmi velkých datových bloků. Pokud je dostupná jen jedna I/O fronta (kanál), proces zálohy tento kanál kompletně zahltí a databáze se prakticky zastaví.
Více kanálů tento problém zásadně omezuje a AHV turbo automaticky definuje optimální počet kanálů podle množství vCPU. Tyto dvě technologie výrazně zrychlují odezvy diskového subsystému a jejich přínos je zejména markantní při použití NVMe disků.
- RDMA
Remote Direct Memory Access (RDMA) umožňuje využít RDMA over Converged Ethernet (RoCEv2) protokol, a tak výrazně snížit latence TCP/IP pro zápisové operace tak, že RDMA zapisuje redundantní data přímo na druhý nod. Technologie RDMA nejen výrazně snižuje latence, ale i dramaticky snižuje zatížení CVM při zápisových operacích.
Technologie Data Locality, AHV Turbo a RDMA mají výrazně pozitivní dopad na propustnost a latence celého prostředí a umožňují naplno využít potenciál technologií NVMe, Intel Optane apod.
- vNUMA
Moderní servery na bázi procesorů Intel mají přiřazené oddělené paměťové banky k jednotlivým procesorům. V případě, že jeden procesor potřebuje obsloužit paměťový blok, který mu není přiřazený, musí požádat jiný procesor, aby tuto operaci obstaral. Negativní dopady technologie NUMA (Non Uniform Memory Access) se v běžných případech vůbec neprojeví, nicméně extrémně velké virtuální stoje mohou mít závažné problémy s tím, že se jednotlivé procesory vzájemně zatěžují paměťovými operacemi. Aby k tomu nedocházelo, Nutanix obsahuje funkci vNUMA. Tato technologie umožňuje virtuálnímu stroji respektovat fyzickou architekturu a předejít vzájemnému negativnímu ovlivňování jednotlivých procesorů. Tato technologie je klíčová pro provoz extrémně velkých VM jako je např. SAP HANA.
- Podpora GPU
Moderní systémy pro náročné výpočty často využívají GPU pro offloadování výpočetní zátěže. Nutanix nabízí možnost využití celé škály GPU a je ho možné přiřadit jak fyzicky, tak je možné GPU virtualizovat, sdílet a přiřadit jednotlivé virtuální GPU (vGPU) mezi více systémů, což může přinést úsporu počtu fyzicky nasazených GPU a zásadně zefektivnit jejich využití.
Scale Out Storage services
- Nutanix Files
Ve virtuálních prostředích je často výhodné používat diskové úložiště nejen jako blokovou storage, ale také jako NAS. Nutanix nabízí možnost využít snadno konfigurovatelnou službu Nutanix Files, která podporuje SMB 2.1 a NFS v4 a její hlavní výhody jsou zejména snadná konfigurace i rozšiřování, pohodlná správa a automatický balancer.
- Nutanix Objects
Podobně jako Nutanix Files, Nutanix Object je automaticky definovaná a load balancovaná služba objektové storage ve standardu S3 kompatibilní s REST API.
Výhoda obou systémů je snadná správa, snadné nasazení a vyzkoušený referenční provoz v prostředí s petabyty dat.
Advanced Virtual Networking
Aby bylo možné jednotlivé systémy bezpečně a spolehlivě propojit jak mezi sebou, tak s okolní infrastrukturou, Nutanix používá technologii vSwitch plně integrovanou do managementu a workflow prostředí Nutanix AOS a Nutanix Prism. Použití technologie vSwitch umožňuje jednoduché nastavení a správu virtuálních segmentů.
- Nutanix Flow
V některých případech je vhodné doplnit segmentaci o funkce bezpečnosti aplikací, detekce provozu a rozšíření bezpečnostních funkcí pomocí řešení třetích stran. Všechny tyto problémy řeší Nutanix Flow, který umožňuje správu a nasazení aplikačního firewallu i mikrosegmentace jak na úrovni VM, tak na úrovni jednotlivých služeb.
V případě, že není komunikace VM a služeb dostatečně dokumentovaná, Nutanix Flow umožňuje běh v permisivním módu a sám dokumentuje komunikační procesy. Když je mapování dokončeno, je velmi jednoduché vytvořit aplikační pravidla a pravidla pro komunikaci s okolní infrastrukturou. Nutanix Flow navíc obsahuje API, které umožní hlubší spolupráci s existujícím podporovaným bezpečnostním řešením
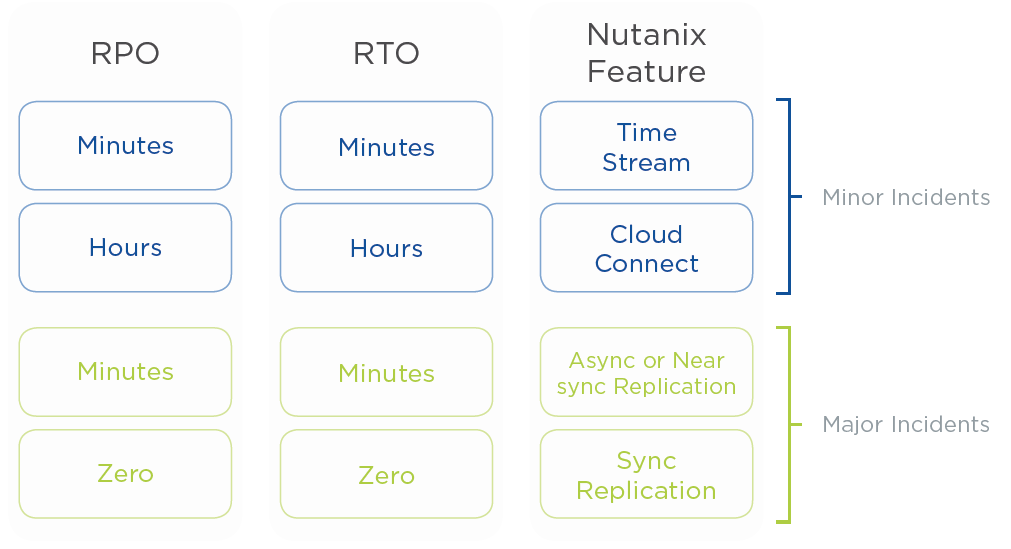
Funkce pro zajištění vysoké dostupnosti a ochrany lokality
Pro zajištění ochrany celé lokality nabízí Nutanix několik strategií:
- Asynchronní replikace
Nutanix nabízí možnost replikace na vzdálený Nutanix Cluster ev. Cloud v časové periodě dny až 1h. Výhodou je velmi jednoduché nasazení, nenáročnost na datovou linku a minimální zátěž produkčního prostředí.
- Near Sync replikace
Near sync replika je velmi podobná asynchronní replice, s replikací v řádech minut. Je možné ji výhodně použít pro replikace na linkách, které jsou rychlé, ale mají velmi velkou latenci.
Asynchronní a Near sync replikace mají zásadní výhody ve velmi jednoduché implementaci, snadném dohledu a jasné orientaci na virtuální stroj. Kompletní konzistentní skupiny jsou definované na VM a podporují i pre / post skripty, pokud to aplikace vyžaduje. Velmi příjemná vlastnost je také to, že v případě řízeného přechodu nedojde k žádné ztrátě dat. Všechna data se doreplikují k poslednímu momentu před startem v druhé lokalitě. Async a near sync repliky se dají definovat v konfiguraci 1:1, nebo 1:Many. Failover a Failback jsou vzájemně ekvivalentní operace, a proto nejsou přechody do DR ani zpět žádný problém. VM je možné obnovit jak z lokální, tak i ze vzdálené repliky, je tak výhodné využít např. pomalejší lokalitu s větší kapacitou jako úložiště s mnohonásobně delší retencí.
Synchronní replikace
Synchronní replika / Stretched Cluster je náročnější na infrastrukturu, nicméně přináší zajímavé nástroje pro řízení vysoké dostupnosti pro kritická prostředí. Zejména jde o:
- Přechod do prostředí jinou konfigurací sítě
VM lze připravit na start v prostředí, které neodpovídá IP schématu primární lokality.
- Testování DR přechodu za provozu
Test spustí kompletní prostředí v DR lokalitě, ale v odděleném segmentu sítě. Je tedy možné za provozu otestovat funkci DR přechodu, funkčnost VM a následně testovací prostředí zrušit.
- Startovací sekvence
Definice startovací sekvence určuje postup, jak zastavit a spouštět jednotlivé stroje.
Sekvence může definovat paralelní, sériový nebo kombinovaný předpis, jak postupovat při startu celé skupiny virtuálních strojů.
- Terciální lokalita. Witness
V případě požadavku na automatický failover je velmi vhodné použít systém terciální lokality. Technologie Stretched Cluster s sebou přináší nebezpečí, že se v případě rozpojení lokalit obě lokality vyhodnotí jako aktivní. Tato situace se nazývá split brain a může způsobit katastrofální datovou dekoherenci. Terciální lokalita a Witness jednoznačně určí, která lokalita je dostupná a ponese produkční zátěž. Witness VM je velmi malé, nenáročné a podporuje všechny dostupné hypervizory.
- Live VM Migrace mezi clustery
Podobně jako Live VM migrace mezi nody je možné migrovat VM mezi lokalitami a provést Failover bez výpadku provozu.
- Recovery points
Přesto, že účelem synchronní repliky je okamžitý zápis na obou lokalitách, Nutanix periodicky vytváří z bezpečnostních důvodů body obnovy na obou lokalitách. Přechod tedy nemusí být nutně k poslednímu momentu, ale možné přejít ke konkrétnímu času - Point in time recovery. Je tak možné provést obnovu posledních správných dat.
Ostatní zajímavé funkce
Systém pro správu aktualizací - Nutanix LifeCycle Manager (LCM)
Nutanix LCM řeší kompletní správu aktualizací i firmware. LCM automaticky detekuje jednotlivé verze biosu, firmware a verzí jednotlivých komponent a automaticky definuje postup aktualizace. LCM také automaticky kontroluje vzájemný soulad verzí, měří, zda není Nutanix kriticky přetížen mimo doporučenou hranici a zda je tedy možné provést update bez výpadku.
LCM zároveň detekuje a automaticky řeší závislosti, takže například nedovolí upgrade AOS na nepodporované verzi firmware. Pokud dojde k nutnosti přechodu o více verzí, LCM automaticky vytvoří rolling update. LCM rovněž upozorní, když se blíží konec podpory aktuálně provozovaných verzí.
Komplexní periodická kontrola systému Nutanix Cluster Check (NCC)
NCC periodicky kontroluje provoz a nastavení celého prostředí. Detekuje tak skryté výpadky infrastruktury, nastavení prostředí mimo optimální hodnoty nebo nedostatky v bezpečnostním nastavení. Všechny testy, které jsou vyhodnoceny jako chyba, bezpečnostní riziko nebo neočekávaná hodnota, odkazují na jednoznačný postup v řešení problému a konkrétní číslo Nutanix KB s dalšími informacemi.
______________________________________________________________________________